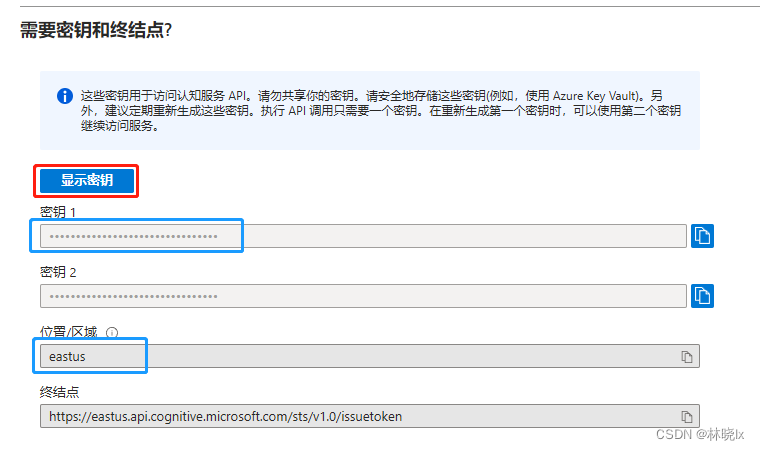
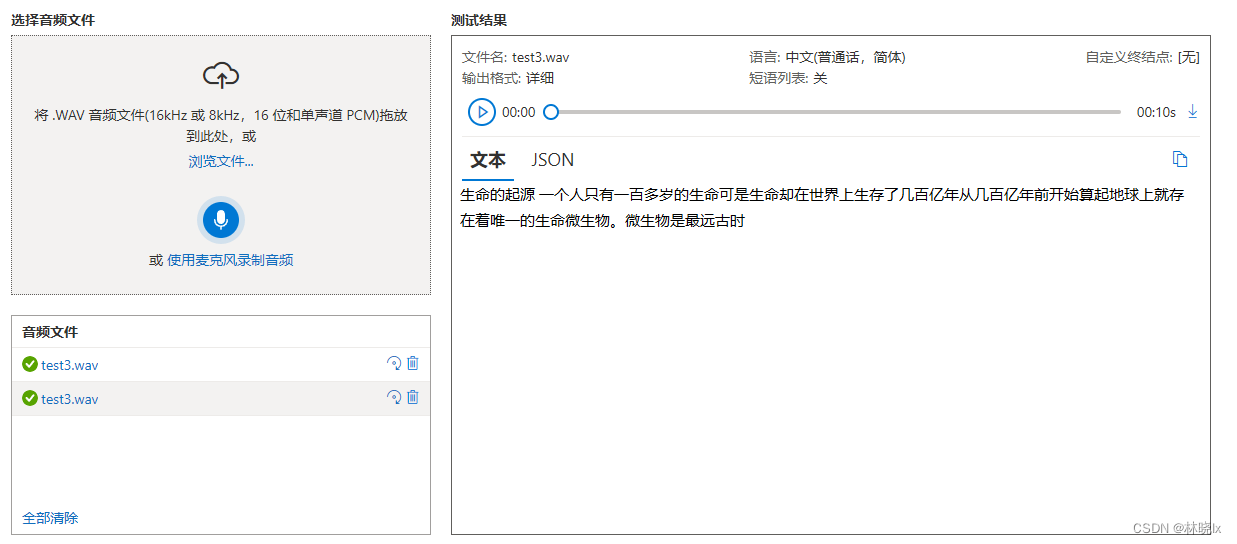
audio2 = speech_recognition.AudioFile("{}".format("test3.wav")) recognizer = speech_recognition.Recognizer() with audio2 as source: audioData = recognizer.record(source) result = recognizer.recognize_azure(audioData,key="<your api key>",language="zh-CN",location="eastus") withopen('test.txt', 'w') as file: if result.__len__()>0: file.write(result[0])
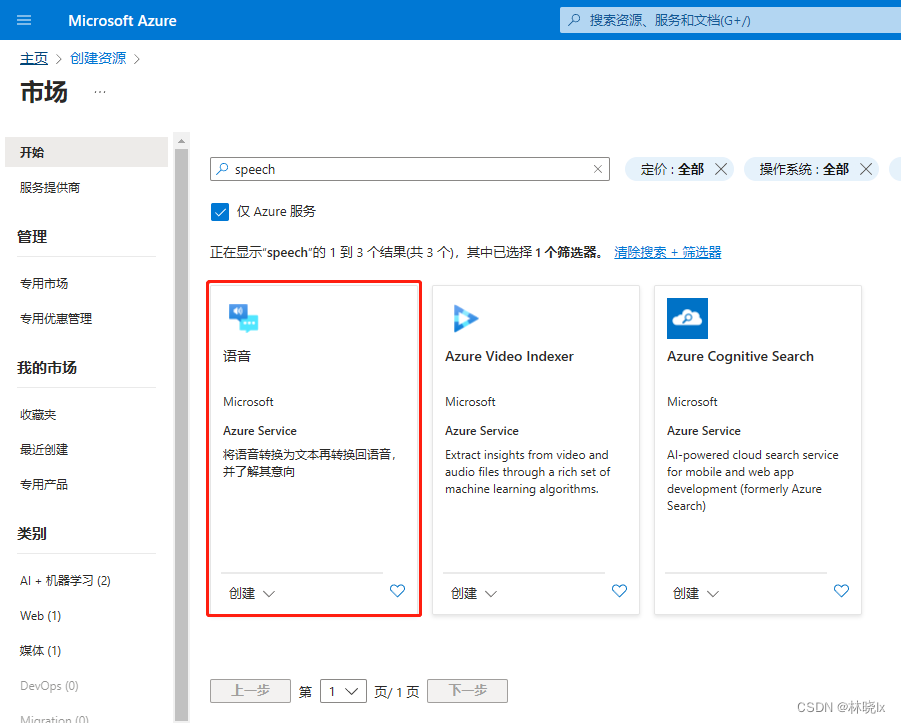
完整代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import speech_recognition import moviepy.editor
videoClip = moviepy.editor.VideoFileClip(r"{}".format("test.mp4")) videoClip.audio.write_audiofile(r"{}".format("test2.wav")) audio2 = speech_recognition.AudioFile("{}".format("test2.wav")) recognizer = speech_recognition.Recognizer() with audio2 as source: audioData = recognizer.record(source) result = recognizer.recognize_azure(audioData,key="<your api key>",language="zh-CN",location="eastus") withopen('test.txt', 'w') as file: if result.__len__()>0: file.write(result[0])